


Aus dem Internet-Observatorium #95
Googles KI-Salat: Peinlich oder auch gefährlich? / LLMs als Kulturtechnologie / Digitale Diplomatie / Datenkauf durch Geheimdienste

Hallo zu einer neuen Ausgabe! Einige werden das hier im Nachgang der Re:publica lesen - Grüße an alle, denen ich über den Weg gelaufen bin. Wen ich verpasst habe: hoffentlich spätestens nächstes Jahr dann oder zu anderer Gelegenheit (einfach melden)!

Googles KI-Salat: Peinlich oder auch gefährlich?
Google hat in den USA seinen KI-Assistenten in die Suche integriert (“AI Overview”) - und die Ergebnisse sind bisweilen skurril.
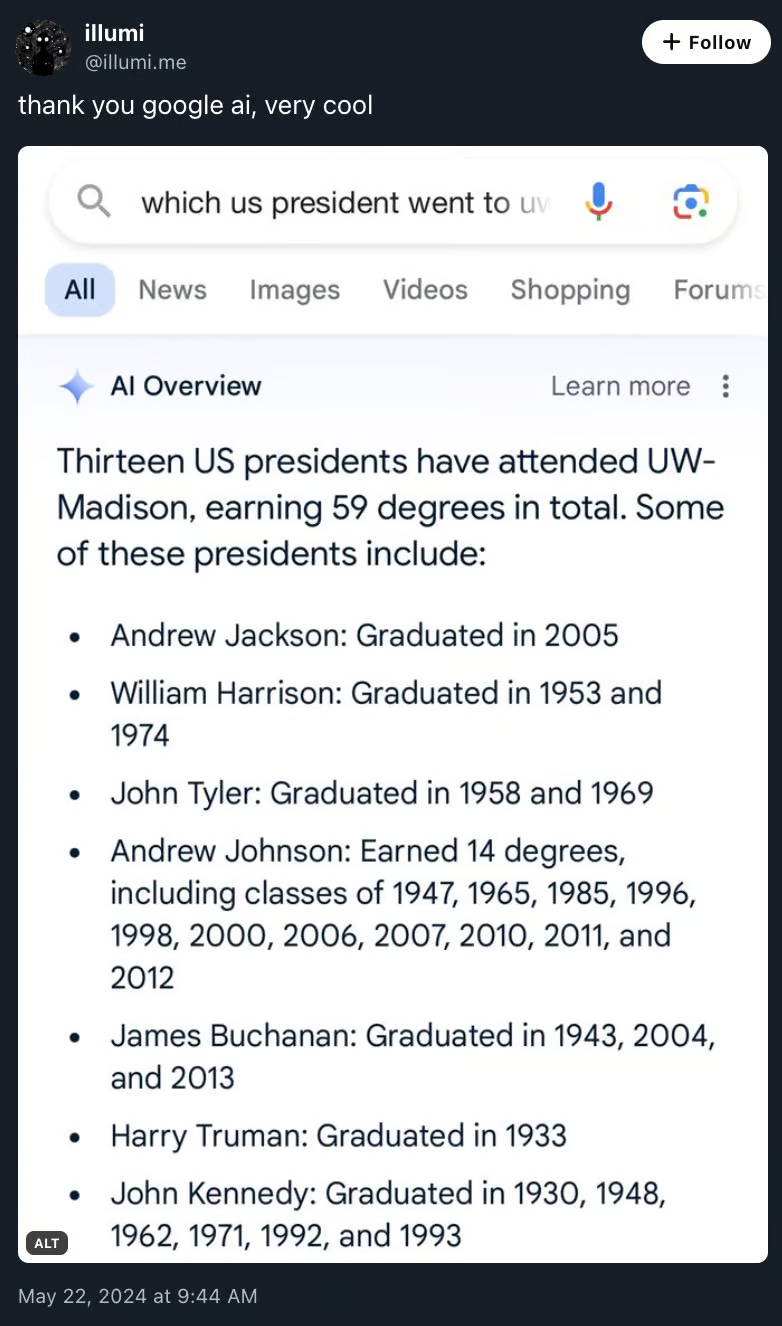
Mir ist noch nicht ganz klar, was genau passiert. Auf schlechte Trainingsdaten deutet ein anderes Antwort-Ergebnis hin, das gerade die Runden macht: Dort empfiehlt das Google-System, Käse auf einer Pizza mit Hilfe von nicht-essbarem Klebstoff zu befestigen. Offenbar stammt der Vorschlag 1:1 aus einem mehr als zehn Jahre alten Reddit-Thread des Nutzers “fucksmith”. In einem ähnlichen Fall übernahm der “AI Overview” Informationen aus einem Text der Satireseite The Onion.
Ein paar Aspekte dazu:
Mike Caulfield beschreibt den Kontext-Kollaps, der sich in Googles KI-Antwortmaschine abspielt: In einer Linkliste sehe ich an den verschiedenen Ergebnissen, ob eine Antwort auf meine Pizza zum Beispiel ein Witz, ein Rezept oder irgendeine andere Form von Inhalt transportiert. Ich kann auswählen. Das fällt hier weg.
Warum aber schafft es Google hier nicht, die richtigen Antworten auszuwählen? Immerhin hat man ja schon länger ein System für Fakten-Antworten (der berühmte Kasten, der sich oft an Wikipedia orientiert).
Offenbar orientiert sich die KI offenbar nicht einem fertigen Corpus (also dem “Wissen” der KI), sondern durchkämmt die wichtigsten Suchergebnisse, die Google ausspuckt. Die KI agiert also als Suchagent, der die Ergebnisse zu einer Antwort destilliert. Offensichtlich tut sich das System jedoch schwer, “unechte” und “echte” Sprache zu unterscheiden - also Ironie zu erkennen. Und auch sonst bringt es einiges durcheinander.
Die Frage ist: Was bedeutet das? Charles Arthur weist darauf hin, dass Google jeden Tag etwa 15 Prozent neue Suchanfragen bekommt, die so noch nie gestellt wurden. Die Zahl ist von 2017 - aber wenn wir annehmen, dass sie ungefähr weiterhin stimmt, macht das Millionen von neuartigen Anfragen jeden Tag aus. Der Teil davon, der in eine KI-Antwort mündet, trägt prinzipiell das Risiko in sich, falsche Informationen zu synthetisieren. Die händische Korrektur, von der Google jetzt also spricht, gleicht also einer Sisyphos-Arbeit.
Was zu der weiteren Frage führt: Wie stark kann Google überhaupt nachsteuern? Sicher, The Onion aus der Liste zu nehmen, ist kein großes Problem. Aber es gibt ja durchaus Argumente dafür, dass große Sprachmodelle sich überhaupt nicht als Antwortmaschinen eignen - weil ihr Antwort-Prozess mehr stochastisch als semantisch ist. Google arbeitet wahrscheinlich gerade an einer Lösung, in der man die Trainingsdaten-Auswahl verändert. Theoretisch ließe sich das System auch im Backend mit einer zweite Prüf-KI ergänzen, allerdings nehme ich an, dass es hier noch Probleme mit der Latenz und vor allem mit den Kosten geben könnte. Denn KI-Antworten sind teuer.
Derzeit drängen die Tech-Firmen ja mit ihren KI-Funktionen auf den Markt im Bewusstsein, dass das alles noch nicht gut ist. “Gut genug” würde allerdings angesichts der Marktmacht oft reichen. Doch ab wann dieser Status erreicht ist - 90 Prozent, 95 Prozent, 99 Prozent korrekter Suchergebnisse - lässt sich schwer sagen.
Google wird das Qualitätsproblem von “AI Overview” nicht auf die leichte Schulter nehmen. Denn es geht nicht nur um schlechte PR und den Eindruck, das eigene Kernprodukt zu zerstören. Sondern, darauf weist Caroline Mimbs Nyce im Atlantic hin, um reale Gefahren. Denn es ist ein Unterschied, ob ich eine schlechte Antwort auf die Frage “Welchen Bluetooth-Speaker soll ich kaufen” oder auf die Frage “Sollte ich das Abnehmmedikament Ozempic nehmen?” erhalte.
Medizinische Fragen spart Google nicht aus und hatte sie ja schon in der Antwortbox, die sich direkt auf Web-Texte bezieht. Jetzt aber verändert sich die Darstellungsform: Google wird zum Antwort-Lieferanten ohne Kontext. Damit, so argumentiert A.W. Ohlheiser bei Vox.com, könnte sich in den USA auch Haftungsfrage ändern: Denn bislang sind Plattformen davor geschützt, wegen der Inhalte ihrer Nutzer verklagt zu werden. Hier aber veröffentlicht Google selbst die Antwort, ohne Bezug auf Dritte.
“Overview AI” wird sich in Anmutung und Funktionalität sicher noch verändern. Dass Google das Feature in die Tonne wirft, erscheint zwar möglich, ist aber sehr unwahrscheinlich (auch wegen der internen Fragen rund um Management und CEO, die daran hängen würden). Und auch der geplante “gesteuerte Niedergang” (“managed decline”, Begriff via Casey Newton) des WWW wird dadurch nicht gestoppt. So bleibt vor allem Ironie, dass nun Google die rapide nachlassende Qualität der Suchergebnisse selber auf die Füße zu fallen scheint.
Große Sprachmodelle als Kulturtechnologie
Henry Farrell ist einer meiner Lieblingsblogger. Und er ist einer der wenigen Politikwissenschaftler, die wirklich intensiv an der Schnittstelle zwischen Politik und digitaler Gesellschaftsveränderung arbeiten und das große Ganze im Blick behalten.
Aktuell beschäftigt er sich mit der Idee der Kognitionspsychologin Alison Gopnik, große Sprachmodelle (LLMs) als Träger von Kulturtechnik/Kulturtechnologie zu betrachten. In diesem Vortrag gibt er eine detaillierte Einführung:
Gopnik argumentiert, dass LLMs nicht zum Lernen im menschlichen Sinne fähig sind - sie sind der realen Welt nicht in einer Form ausgesetzt, die für ein echtes “Verstehen” notwendig wäre. Anders als Menschen und auch Tiere lässt sich bei LLMs nicht von einer intentionalen Kognition sprechen - also von Prozessen, die sich mit Absichten, Zielen und Zwecken verbinden. Was LLMs können: Sie ermöglichen neue Methoden für Nutzung, Zugang und Remix des vorhandenen menschlichen Wissens.
Damit lässt sich auch die Vorstellung beseitigen, KIs seien in irgendeiner Form individuelle “Akteure” - sie lassen sich in diesem Kontext eher als Technologien unserer gesammelten, kollektiven Intelligenz. Ob ein KI-System halluziniert oder die richtige Antwort liefert, ist in der Logik des Systems entsprechend unwichtig. Letztlich ordnet es einfach bestehendes “Wissen” an oder neu an.
In einem Blogeintrag fasst Farrell zusammen, was für ihn die Konsequenzen dieses “Gopnikism” sind (übersetzt und gefettet):
“Kultur - in diesem Sinne - ist kollektives menschliches Wissen, das durch eine Vielzahl von Mitteln bewahrt, weitergegeben und organisiert wird. Am einfachsten wird es weitergegeben, wenn Menschen einander direkt beobachten können, aber im Laufe der Jahrtausende haben wir auch komplexere Technologien zur Übertragung entwickelt. Sprachen, Geschichten, Bibliotheken und dergleichen ermöglichen die Übermittlung und Organisation von Informationen.
Jetzt gibt es eine neue Technologie für die kulturelle Übermittlung - LLMs. Der riesige Text- und Datenkorpus, den sie aufnehmen, ist eine Reihe unvollkommener Momentaufnahmen der menschlichen Kultur. Der Gopnikismus unterstreicht, dass wir darauf achten sollten, wie LLMs diese kulturellen Informationen übertragen, rekombinieren und neu organisieren können und welche Folgen dies für die menschliche Gesellschaft haben wird.”
Meine Vorstellung dazu: Eine Druckerpresse, deren Output aus nicht (kaum? noch nicht? nur von wenigen?) prognostizierbaren Mixen und Remixen des digital zugänglichen menschlichen Wissenskorpus besteht.
In seinem Vortrag erinnert Farrell an den Satz “Die Karte ist nicht das Gebiet” - was ein Computer ausgibt, ist nicht die Sache selbst. Nun aber, folgert er, kommen wir in eine neue Phase: Die Karte drängt nicht nur auf das Gebiet, sie kann es sogar verschlingen. Denn selbstverständlich verändert sich auch das Weltwissen, wenn es von der KI nicht nur eingesaugt, sondern auch produziert wird.
Der neue Klassenkampf ist demnach kein Kampf um das Eigentum der Produktionsmittel (Marx), sondern um die das “Eigentum der Zusammenfassung”.
Farrell hütet sich davor, einen neuen Feudalismus durch die wirtschaftliche Abhängigkeit von KI-Systemen zu prognostizieren - die Geschichte zeigt ihm, dass die Zukunft nur selten den Extremvorstellungen entspricht. Er sieht jedoch dennoch eine drängende Aufgabe darin, sich mit den Folgen für Systeme der Wissens- und Kulturproduktion intensiv und interdisziplinär auseinanderzusetzen.
Geheimdienste und die Daten: Alte und neue Lücken
Der scheidende Bundesdatenschutzbeauftragte Ulrich Kelber hat den Bundesnachrichtendienst verklagt - es geht um den Zugang zu Informationen über ein System der Datenverarbeitung (von Daten ausländischer Menschen). Details bei Netzpolitik und Süddeutsche Zeitung (€) und im Deutschlandfunk, wo ich den Grundkonflikt angerissen habe.
Vor der anstehenden Reform des Nachrichtendienstrechts wirft das nochmal ein Schlaglicht auf die - trotz bereits erfolgter Reformen - komplexe und doch unbefriedigende Geheimdienstkontrolle in Deutschland. Christoph Koopmann listet die Zuständigkeiten in der SZ auf:
“Der BfDI ist für Datenschutzbelange beim BND, beim Verfassungsschutz und beim Militärischen Abschirmdienst zuständig. Dazu kommt die G-10-Kommission, benannt nach Artikel 10 des Grundgesetzes, der das Fernmeldegeheimnis regelt. Dieses Gremium entscheidet, ob die Agenten Mails von deutschen Staatsbürgern und ausländischen Zielpersonen in Deutschland mitlesen oder Telefonate mitschneiden dürfen.
Dazu kommt beim BND der Unabhängige Kontrollrat. Dieses Richtergremium prüft, welche Telekommunikationsdaten der BND im Ausland überwachen darf. Und dann gibt es noch das Parlamentarische Kontrollgremium des Bundestags, dessen Abgeordnete den Überblick über alles Wichtige haben sollen, was in den deutschen Diensten abläuft.”
Viele gucken, aber niemand hat den Überblick. Der Bundesdatenschutzbeauftragte darf Probleme bemängeln, aber nicht deren Korrektur anweisen. Und beim Unabhängigen Kontrollrat (UK) stellt sich inzwischen sogar öffentlich die Frage, ob das Gremium seiner Kontrollaufgabe wirklich in einer angemessenen Form nachkommt.
Und da ist da noch die Sache mit dem Datenkauf: Denn wenn deutsche Geheimdienste auf dem freien Markt Datenpakete über einzelne Personen oder gar komplette Datenbanken kaufen, gibt es derzeit noch keinen rechtlichen Rahmen dafür. Kurz: Alles ist erlaubt. Das sollte - gerade angesichts der aus dem Ausland bekanntgewordenen Beispiele - dringend geändert werden.
Die Stiftung Neue Verantwortung hat ein ganzes Paket von Vorschlägen vorgelegt, wie man das Nachrichtendienstrecht reformieren sollte. Gerade weil das Thema so schlecht beleuchtet ist, sollten wir Digitalinteressierten uns mit den Problemen und möglichen Lösungsvorschlägen vertraut machen.
Digitale Diplomatie - ein Spiegel der Diskurskultur?
Es gibt eine ganzes politisches Genre, das sich mit der Rolle von öffentlicher Diplomatie und medial aktiven diplomatischen Vertretungen im Social-Media-Zeitalter beschäftigt. Ich verfolge das mit Interesse, weil wir tatsächlich unterschätzen, wie Social-Media-Strategien und -Dynamiken letztlich auch den öffentlichen Auftritt von diplomatischen Vertretern und Vertreterinnen inzwischen prägen.
Ilan Manor, Autor des jüngst erschienenen “Oxford Handbook of Digital Diplomacy”, sieht dabei einen großen Trend (übersetzt):
“Es ist wirklich bemerkenswert, wie die Logik des Getrenntseins die Logik der Relationalität verdrängt hat.”
Drei Entwicklungen zählt er dazu:
Eine Form von digitaler öffentlicher Diplomatie, die sich immer stärker dem eigenen, nationalen Publikum zuwendet, statt in den Dialog zu gehen. Was osft auch mit Othering (also “die Anderen”, über die gesprochen wird) einher geht.
Eine stärkere Ästhetisierung von Krieg, zum Beispiel durch Fotos von Kampfflugzeugen in heroischem oder spektakulär aussehenden Umfeldern oder im Falle des Ukraine-Kriegs von herabsetzende Aufnahmen von Soldaten oder Gerät des Gegners.
Und schließlich ein vermehrt kämpferischer und herabsetzender Ton auf öffentlichen digitalen Diplomatie-Kanälen.
Vom einstigen Ideal digitaler Diplomatiekanäle als Form von bi- oder multilateraler symbolischer Kommunikation ist also nicht mehr viel übrig. Stattdessen erlebten wir, so Manor, wie dieses neue Werkzeug auf die Größe eines weiteren PR-Megafons schrumpft.
Notizen
Schattenbericht zu Schumers AI Roadmap: Vor zwei Wochen veröffentlichte eine Arbeitsgruppe des US-Senats ihre Empfehlungen für eine KI-Roadmap. Ich hatte noch keine Zeit, mich länger einzulesen, aber die Reaktionen waren sehr kritisch: Letztlich sei es der Tech-Branche mit dem Drängen auf diesen Bericht gelungen, das Momentum für KI-Regulierung zu stoppen. Zudem sei die Zivilgesellschaft, anders als in den ersten Phasen der Diskussion, nur noch unzureichend einbezogen gewesen. Ein Bündnis aus NGOs wie Access Now hat inzwischen einen “Schattenbericht” veröffentlicht, der natürlich deutlich stärkere Regulierung fordert. Was bleibt: Bis zum Januar 2025 wird nichts mehr passieren und Mehrheit und Momentum danach sind ungewiss.
Quo Vadis, Trust and Safety? Tyler Cohen interpretiert den Schumer-Bericht und seine unternehmensfreundliche Botschaft als Zeichen dafür, dass die AI-Safety-Bewegung erst einmal tot ist ($). Das ist natürlich erst einmal nur eine These, aber derzeit scheint insgesamt im Bereich Trust & Safety im Umbruch, wie Katie Harbath schreibt. Dazu gehören in den USA Entlassungen in den entsprechenden Abteilungen bei den Tech-Großfirmen, aber auch ein Generationswechsel im T&S-Feld. Es ist insgesamt mehr Expertise vorhanden, aber die Themen in Sachen Moderation werden auch komplexer (Nahost-Konflikt etc.). Außerdem gibt es offenbar von öffentlichen Institutionen weniger Geld für Projekte. Ich kann das noch nicht zusammenpuzzeln, aber die Entwicklungen sollte man im Auge behalten.
Scarlett Johansson - es war komplizierter: Die Washington Post hat das Drama (siehe Ausgabe #94) zu rekonstruieren versucht ($) und dabei auch Dokumente von OpenAI erhalten. Demnach wurde die “Sky”-Darstellerin nicht gebeten, wie Johannson zu klingen und sieht auch keine Parallelen zu ihr, außer einer gewissen rauen Stimme. Allerdings bleibt natürlich auch die Tatsache, dass OpenAI-Chef Sam Altman zweimal bei Johannson fragte, ob sie der KI nicht ihre Stimme geben würde. Und sein Tweet “Her” rund um die Präsentation von GPT-4o dürfte in einem eventuellen Zivilprozess auch keinen guten Eindruck hinterlassen.
Eine Grafik
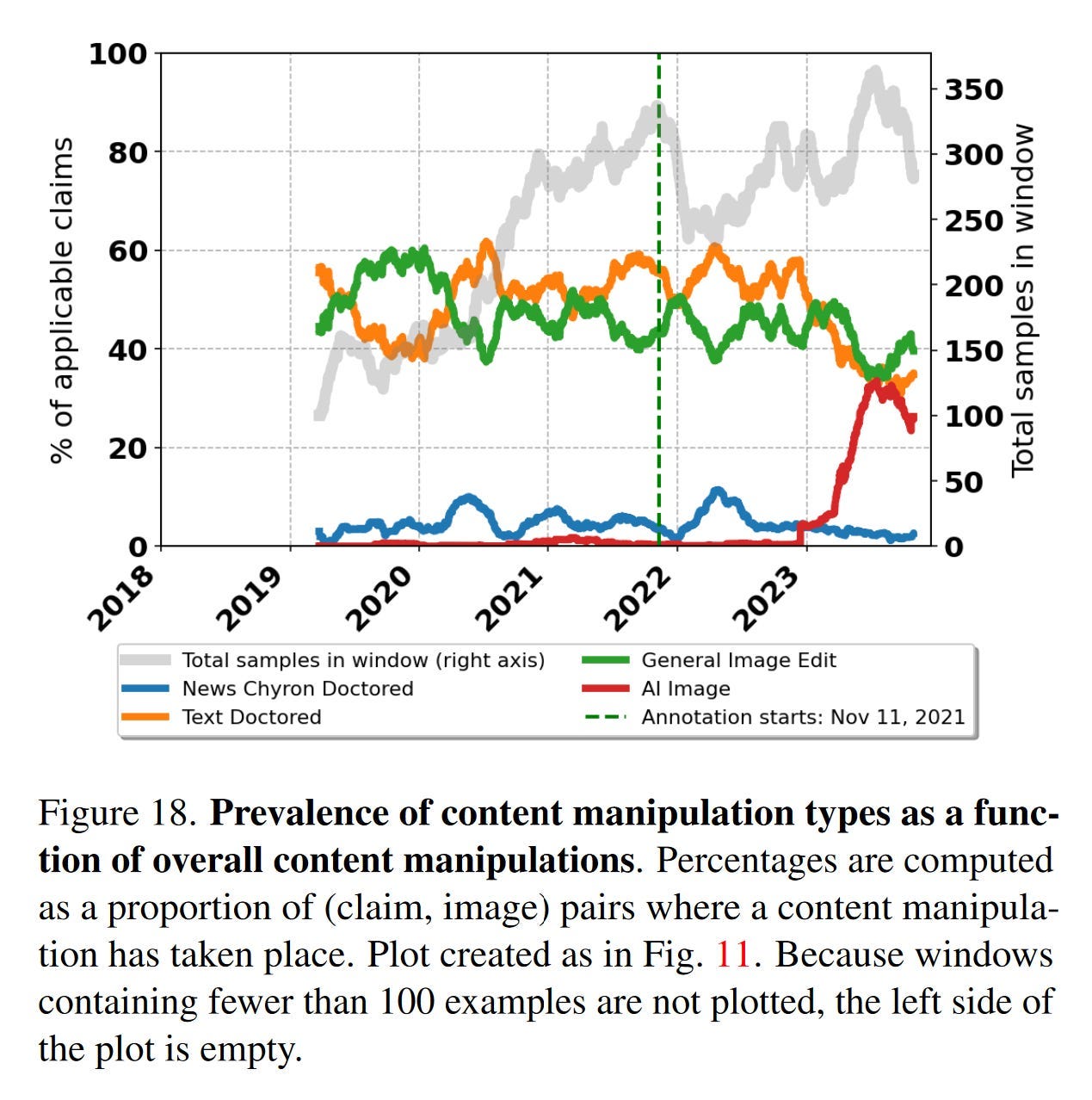
Diesem Paper von Google-Forschern (noch im Preprint) zufolge sind KI-basierte Bilder bei manipuliertem Content auf dem Vormarsch (siehe rote Linie). Die Untersuchung bezieht sich rein auf von Faktencheckern wie Snopes überprüfte Inhalte.
Ein Bild

Weil wir beim Thema sind: Das XTwitter-Konto “Insane Facebook AI Slop” (“verrückter Facebook KI-Klärschlamm”) sammelt Screenshots von Facebook-Postings mit völlig bizarren KI-Bildern (die aber Likes ohne Ende sammeln). Mehr zu Facebooks KI-Spamproblem in Ausgabe #93.
Links
DSA: EU überprüft strengere Einstufung von Telegram.
FTC-Chefin deutet Wettbewerbsntersuchung von Herstellern großer Sprachmodelle an.
Googles interne Dokumentation des Such-Algorithmus stand offenbar zwei Monate lang bei Github.
Nachfolge-Erklärung von Bletchley Park in Seoul unterzeichnet.
Quartz, Cobalt und den Müll, den wir zurücklassen.
Markus Beckedahls Re:publica-Keynote.
KI-Finanzanalyse >= menschliche Finanzanalyse.
Die Trainingsdaten-Deals der Verlage mit KI-Anbietern: ein Überblick.
Die Zukunft der Foundation Models ist Closed Source.
Transparenz der aktuellen Foundation Models - eine Liste.
Zwei ehemalige Board-Mitglieder von OpenAI über die Ära Altman.
Vorschläge zur Umsetzung des AI Acts und zum AI Office.
Reverse Engineering forgotten Crypto-Passwords.
Google Gemini: Oder denkt es doch? (€)
Bis zur nächsten Ausgabe!
Johannes