


Aus dem Internet-Observatorium #73
Notizen zum OpenAI-Machtkampf / AI Act / Synthetischer Content, gefälschte Studien

Hallo zu einer neuen Ausgabe! Da vergangene Woche wegen Terminen ausfiel, komme ich nicht um OpenAI herum - auch wenn die Zahl an Analysen, Pseudo-Analysen und Hot-Takes selbst ohne mein Zutun bereits gewaltig war. Fun fact am Rande: Am Donnerstag jährt sich die Veröffentlichung von ChatGPT zum ersten Mal.

Notizen zum Machtkampf bei OpenAI
Das Chaos bei OpenAI war das Thema der vergangenen Woche. Trotz intensiver medialer Berichterstattung ist nicht so wirklich klar, was passiert ist. So kursieren immer noch unterschiedliche Interpretationen, ob die Altman-Gegner aus dem Board letztlich gescheitert sind, oder das eigentliche Ziel - Sam Altman und seinen Compagnion Greg Brockman aus dem Gremium zu entfernen - in einer Art Kamikaze-Mission erreicht haben.
Wer die Wendungen nachvollziehen möchte, dem/der empfehle ich die Timelines bei Axios und im Social Media Watchblog. Ich selbst will mich nur auf ein paar Notizen beschränken.
Motive der Mitarbeitenden
Wichtig zu verstehen: OpenAI wurde einmal als gemeinnützige Organisation gegründet, hat das dann aber aus finanziellen Gründen hinter sich gelassen. Es gibt aber diesen gemeinnützigen Teil noch, der hat sogar die Mehrheit an OpenAI. Und wer vertritt diesen gemeinnützigen Teil? Das Board.
Eines der Narrative aus der vergangen Woche war: Die Skeptiker einer allzu schnellen KI-Entwicklung im Board wollten Altman loswerden, was wiederum jene 700 der etwa 800 Mitarbeitenden verhinderten, die aus Loyalität mit ihrem (zwischenzeitlich Ex-)Chef in einem Brief mit Kündigung drohten. OpenAI wäre im Falle von Massenkündigungen nur noch eine leere Hülle gewesen, zumal die meisten Leute in Altmans neues Team bei Microsoft gewechselt wären.
Aber ging es wirklich um Loyalität? Ein Leser des kundigen Bloomberg-Kolumnisten Matt Levine stellt eine andere These auf: Es ging womöglich schlicht um die Bewertung von 86 Milliarden US-Dollar. Zitat (übersetzt):
“Das Board besteht aus KI-Evangelisten; der Grund, warum sie offen darüber besorgt sind, dass KI zu mächtig wird, liegt in dem Glauben an das Potenzial einer gottgleichen KI oder zumindest in der Sorge, dass diese bald allgegenwärtige Technologie in bester Form sein sollte, bevor sie der Welt zur Verfügung gestellt wird. Die Mitarbeiter hingegen kennen alle Einschränkungen, Probleme und Kosten der KI und sind - als Veteranen des Silicon Valley - auch mit dem hier herrschenden Hype-Zyklus vertraut.”
Dazu passt auch der Zeitpunkt: Denn im Oktober wurde bekannt, dass Thrive Capital plant, Mitarbeiter-Aktien zu kaufen. Und zwar zum Marktwert von 86 Milliarden Euro.
Dieser Deal wäre nach dem CEO-Wechsel nicht in dieser Form zustande gekommen, die Firma wäre deutlich niedriger bewertet worden, sofern sie in dieser Form noch existiert hätte. Entsprechend hatten die Mitarbeitenden ein finanzielles Motiv, sich für Stabilität an der Spitze einzusetzen. Der Aktien-Verkauf wird nun wie geplant vonstatten gehen, wie The Information ($) meldet.
Microsoft, Investoren und die Zukunft des Boards, die Frage der Kontrolle
Das gemeinnützige Board war vor der Krise nicht mit Investoren besetzt. Und ist es derzeit weiterhin nicht, auch wenn der ehemalige amerikanische Finanzminister Larry Summers nicht das Lager der KI-Ethiker vertreten dürfte. Möglicherweise drängt Microsoft auf einen Sitz im Board, Ben Thompson spekuliert aber ($), dass man diese Forderung fallen lässt, wenn man genug Rechte an den der OpenAI-Technologie erhält.
Microsoft als Gewinner der ganzen Angelegenheit zu sehen, dürfte nicht zu weit hergeholt sein: Der Konzern kontrolliert Altman und OpenAI jetzt de facto deutlich stärker als zuvor, als man trotz 13 Milliarden US-Dollar Investitionen (vor allem in Form von Cloud-Kapazitäten) kaum Einfluss nehmen konnte und auch vom Coup des Boards überrascht wurde. Vor allem aber muss man sich weiterhin nicht mit Wettbewerbsfragen auseinandersetzen, die eine Übernahme mit sich bringen würde.
Aus der ganzen Angelegenheit folgt die Frage, ob ein derartiges Firmenkonstrukt geeignet war, die Entwicklung einer neuen Technologie zu kontrollieren. Die mehr oder weniger einhellige Meinung lautet: nein. Selbst der Economist, nicht bekannt dafür, besonders große Sympathien für Regulierung zu hegen, schreibt (übersetzt, $):
"Die wichtigste Lehre: Es ist töricht, Technologien mit Hilfe von Unternehmensstrukturen regulieren zu wollen. Als das Potenzial generativer KI deutlich wurde, wurden die Widersprüche in der Struktur von OpenAI aufgedeckt. Eine einzelne Organisation kann nicht das beste Gleichgewicht zwischen dem Vorantreiben der KI, der Anziehung von Talenten und Investitionen, der Bewertung von KI-Bedrohungen und dem Schutz der Menschheit finden. Interessenkonflikte im Silicon Valley sind kaum selten. Selbst wenn die Leute bei OpenAI so brillant wären, wie sie denken, wäre die Aufgabe für sie zu groß."
Wenn wir Vorstand, Board und Investoren zusammenzählen, die hier Einfluss hatten, sind wir bei… anderthalb, zwei Dutzend Menschen? Das ist wenig und das Ergebnis zeigt, dass letztlich die Investoren ihre Wünsche durchgesetzt haben. Das dürfte auch eine Lehre für Ideen wie Selbstregulierung (siehe unten) und Konstrukte sein, die sich ähnliche Aufsichtsstrukturen geben.
Q-Star
Am Ende noch ein paar Worte zu Q* (gesprochen: Q-Star), jenem Algorithmus, der laut OpenAI-Insidern kurz vor der Altman-Kontroverse einen - nicht näher benannten - Durchbruch markierte. Offenbar ging es um die Lösung von mathematischen Problemen, die Königsdisziplin, an der KI regelmäßig scheitert. Übersetztes Zitat Reuters:
“Einige bei OpenAI glauben, dass Q* (ausgesprochen “Q-Star”) einen Durchbruch in der Suche des Startups nach sogenannter künstlicher allgemeiner Intelligenz (AGI) darstellen könnte, sagte eine der Personen Reuters. OpenAI definiert AGI als autonome Systeme, die Menschen in den meisten wirtschaftlich wertvollen Aufgaben übertreffen.
Angesichts umfangreicher Rechenressourcen war das neue Modell in der Lage, bestimmte mathematische Probleme zu lösen, sagte die Person unter der Bedingung der Anonymität, da sie nicht befugt war, im Namen des Unternehmens zu sprechen. Obwohl es nur Mathematik auf dem Niveau von Grundschülern ausführte, machte die erfolgreiche Bewältigung solcher Tests die Forscher sehr optimistisch in Bezug auf den zukünftigen Erfolg von Q*, sagte die Quelle.”
Was genau das sein könnte, wird in Fachforen intensiv diskutiert. Es könnte eine neue Form von Lernen anhand verschiedener Komponenten sein, unter anderem Beispiel Feedback einer zweiten KI (Reinforcement Learning from AI feedback, RLAIF).
Im Kern geht es darum, dass sich generative künstliche Intelligenz zwar Dinge merken kann; der Output aus diesen Informationen aber besteht letztlich nur aus einer Aneinanderreihung der jeweils wahrscheinlichsten nächsten Elemente (Wortketten werden zu Sätzen werden zu Texten, zum Beispiel). Für Sortierfunktionen und die Rekombination bestehender Elemente jeglicher Art ist das genug. Mathematik jedoch funktioniert über die Anwendung von Logik. Und eine KI, die Logik beherrscht würde in der Tat ein folgenreicher Durchbruch.
Ob es sich bei Q* um einen Durchbruch dieser Art handelt, wissen wir natürlich nicht. Genauso gut könnte es eine weitere Nebelkerze sein. Und Karen Hao weist darauf hin ($): Da die Forschung im Verborgenen stattfindet, liegt die Interpretation eines “Durchbruchs” nicht bei der Forschungsgemeinde, sondern im Auge der Betrachter - und das sind in diesem Falle nur die OpenAI-Mitarbeitenden, die von diesem Projekt Kenntnis haben.
AI Act: Auf der Bremse
Am Freitag beraten die EU-Botschafter über den aktuellen Kompromissvorschlag, am 6. Dezember dann soll es eine Einigung zum “AI Act” geben. Allerdings sind die Verhandlungen zuletzt ins Stocken geraten, nachdem Deutschland, Frankreich und Italien in einem Non-Paper fordern, große Sprachmodelle (oder Basismodelle/Foundation Models) nur durch kontrollierte Selbstregulierung in Form eines überprüfbaren Verhaltenskodex zu regulieren. Das ist etwas, was das Europaparlament auf keinen Fall zulassen möchte und auch Experten und Expertinnen heftig kritisieren.
Das Argument hinter dieser sehr laxen Regulierung ist die Standortfrage: Die Sorge ist, dass hohe Auflagen dazu führen könnten, dass überhaupt keine Grundlagenmodelle aus Europa kommen können. Und Firmen letztlich auf amerikanische KI angewiesen sind, die sie dann für ihre Zwecke modifizieren. Man würde also, so wie jetzt bei Google, Meta, Amazon, an den APIs der US-Konzerne hängen.
Es ist kein Geheimnis, dass Frankreich das nebulöse Start-up Mistral (mit dem ehemaligen Digitalminister Cédric O) und Deutschland Aleph Alpha als Akteure sehen, die solche Grundlagenmodelle entwickeln und zu globalen Konzernen werden könnten. Es ist übrigens auch kein Geheimnis, dass im ganzen Regulierungsprozess wieder einmal vor allem die Tech-Firmen das Ohr der Beteiligten in Brüssel hatten (was auch daran liegt, dass die KI-Akteurslandschaft aus Zivilgesellschaft, NGOs und Forschung noch nicht konsolidiert ist, es keine Handvoll eindeutiger “Must-have-”Ansprechpartner gibt).
Es ist natürlich paradox, die relativ ungefährlichen KI-Anwendungsfälle durchzuregulieren und das ausgerechnet bei den großen Basismodellen auszusetzen. Und es wirft Downstream Haftungsfragen auf: Nämlich bei den Firmen, die auf Basis solcher Grundlagenmodelle eigene Software-Angebote entwickeln und nicht garantieren können, dass sie auf einem sicheren Fundament stehen.
Der aktuelle Kompromissvorschlag der spanischen Ratspräsidentschaft sieht Medienberichten zufolge so aus:
Horizontale Verpflichtungen für Allzweck-KI-Modelle: Diese beinhalten die Sicherstellung, dass KI-generierte Inhalte als künstlich erzeugt oder manipuliert erkennbar sind. Die berühmten Wasserzeichen, die sich zum Branchenstandard entwickeln also.
Regulatorischer Dialog und Cybersicherheit für Modelle mit systemischen Risiken: Für diese Modelle sind interne Maßnahmen und Gespräche mit der Kommission zur Identifizierung und Minderung systemischer Risiken vorgeschrieben, einschließlich der Gewährleistung eines angemessenen Niveaus an Cybersicherheit. Offenbar bekommt also das berühmte KI-Büro in Brüssel größeren Einfluss als geplant?
Nachweis der Einhaltung durch Verhaltenskodizes: Modellanbieter können die Einhaltung der horizontalen und spezifischen Verpflichtungen durch Befolgung von Verhaltenskodizes nachweisen. Ein Knackpunkt des Kompromisses, der in dieser Form erst einmal sehr lax klingt.
Informationspflicht für Anbieter von Allzweck-KI-Systemen: Diese müssen oben benannten Downstream-Firmen relevante Informationen bereitstellen, um die Einhaltung des KI-Gesetzes zu gewährleisten, insbesondere wenn ihre Systeme in Hochrisikoszenarien eingesetzt werden. Ich nehme an, dass es sich um eine Form der so genannten “Model Cards” handelt - also dem Branchenstandard mit einigen Basisdaten für die Modelle. Allerdings müssten die Informationen dann deutlich erweitert werden. Auch hier liegt der Teufel im Detail, in Haftungsverträgen und letztlich auch in der KI-Haftungsrichtlinie (AIDL), die separat verhandelt wird.
Synthetischer Content, gefälschte Studien
Wir können die Konturen unseres “synthetischen Zeitalters” (siehe #41) derzeit bereits schemenhaft erkennen. Zum Beispiel plastisch in dem DeepFake von Olaf Scholz, den das “Zentrum für politische Schönheit” am Montag postete. Oder dem gefälschten Pizzamüll-Parteitagsfoto vom Grünen-Parteitag.
Oder auch in diesem Experiment: Wissenschaftler haben ChatGPT verwendet, um testweise Datensätze einer klinischen Studie zu fälschen, die wiederum eine (falsche) Hypothese belegen sollte. Also: Das Ergebnis stand fest, die KI lieferte die Daten.
Charles Arthur, der den Artikel in seinem Newsletter verlinkt hat, postet klugerweise darunter ein Stück aus der Financial Times (€), das grundsätzlich mit dem wachsenden Betrugsproblem in der Forschung beschäftigt. Kurz gesagt: Es besteht ein Ungleichgewicht zwischen der geringen Aufklärungsquote bei wissenschaftlicher Unredlichkeit und den Anreizen für ethische Forschung. Zitat (übersetzt und gefettet):
“Wie die Psychologin der Universität Oxford, Dorothy Bishop, geschrieben hat, erfahren wir nur von denen, die erwischt werden. Ihrer Ansicht nach ist unsere “entspannte Haltung” gegenüber der Epidemie des wissenschaftlichen Betrugs ein “Desaster, das nur darauf wartet, zu geschehen”. Die Mikrobiologin Elisabeth Bik, eine Daten-Detektivin, die sich auf das Aufspüren verdächtiger Bilder spezialisiert hat, könnte argumentieren, dass die Katastrophe bereits da ist: Ihre durch Patreon finanzierte Arbeit hat zu über tausend Rücknahmen und fast ebenso vielen Korrekturen geführt. (…)
Bishop argumentiert, dass es eine richtige Ermittlungseinheit geben sollte, mit einem Heer von speziell ausgebildeten Wissenschaftlern, (…) um die Integrität der Forschung zu schützen. (…)
Dies könnte helfen, den Aufstieg der “Paper Mills”, einer geschätzten 1-Milliarden-Dollar-Branche, zu unterbinden. Dort können skrupellose Forscher Autorenschaften gefälschter Studien kaufen, die für Peer-Review-Zeitschriften bestimmt sind. China spielt eine übergroße Rolle in dieser Praxis, die eine global wettbewerbsfähige “Publish or Perish”-Kultur bedient, die Akademiker daran misst, wie oft sie veröffentlicht und zitiert werden.”
Der Betrug findet also nicht im luftleeren Raum statt. Für mich ergeben sich daraus drei Faktoren, die die Verbreitung von “synthetischem Content” begünstigen - sowohl bei Social Media, als auch in einem Bereich wie dem der wissenschaftlichen Studien.
Die einfache Herstellung mittels KI
Eine unübersichtliche Quellenlandschaft (Online-Journale, Online-Plattformen)
Der falsche Anreiz der Sichtbarkeit (Publish or Perish, Kampf um Social-Media-Aufmerksamkeit)
Fehlende Korrekturinstitutionen (horizontale und vertikale Peer-Review-Lücken, virale Effekte kommen dem Debunking zuvor, das ohnehin nur bedingt hilft).
1 Tabelle
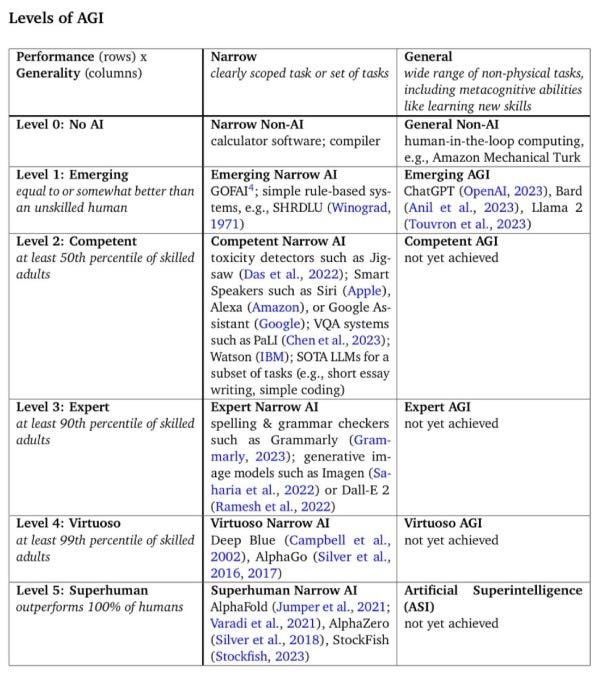
Ali Arsanjani von Google DeepMind hat bei LinkedIn die Abstufungen gepostet, in die seine Firma den Weg zur Künstlichen Allgemeinen Intelligenz (AGI) misst:
Das Alignment-Problem

Einleuchtendes New-Yorker-Cover der KI-Sonderausgabe.
Links
Binance-Gründer Zhao bekennt sich der Geldwäsche für internationale Regime für schuldig.
DeepFakes und die Gefahr eines Nuklearkriegs.
Nein, TikTok-Teenager sind keine Bin-Laden-Fans
Israel: Starlink im Gaza-Streifen nur mit Zustimmung der Regierung. ($)
Die Ukraine nutzt im Krieg mit Russland Clearview AI.
Tech-Konferenz wirbt mit Fake-Speakerinnen, implodiert.
Elon Musks Radikalisierung und der Zusammenhang mit der Corona-Pandemie. ($)
Kanadas Regierung und Google einigen sich über das Leistungsschutzrecht.
Sports Illustrated veröffentlicht KI-Artikel von KI-generierten Autoren(profilen).
Bis zur nächsten Ausgabe!
Johannes