

Aus dem Internet-Observatorium #45
KI-Regulierung: Vertikal ist besser? / Twexit und die logistischen Hürden / Loch im Cookie

Hallo zu einer neuen Ausgabe! In dieser Woche eher Themen aus dem Bereich Policy und Recht. Nächste Woche wieder mehr Internetkultur, versprochen!

KI-Regulierung: Vertikal ist besser?
Es hat sich in diesem Jahr bereits eine Menge getan in Sachen KI-Regulierung: Die EU erreicht beim “AI Act” die - zugegeben lange - Zielgerade. Die US-Standardisierungsbehörde NIST hat die erste Version des “AI Risk Management Frameworks” (RMF) veröffentlicht. Die britische Regierung hat ein Whitepaper zur KI-Regulierung herausgegeben. Und China hat neue Regeln festgeschrieben, die speziell im Umgang mit Chatbots den Konflikt zwischen KI-Supermachtambitionen und Zensuranstrengungen deutlich machen.
Was aber bedeutet Regulierung? Matt O’Shaughnessy und Matt Sheehan haben die zentrale Frage knackig zusammengefasst (Fettungen von mir):
“When policymakers sit down to develop a serious legislative response to AI, the first fundamental question they face is whether to take a more “horizontal” or “vertical” approach. In a horizontal approach, regulators create one comprehensive regulation that covers the many impacts AI can have. In a vertical strategy, policymakers take a bespoke approach, creating different regulations to target different applications or types of AI.”
Die Europäische Union hat als einziger der am Anfang genannten Akteure eine (eher) horizontale Regulierung gewählt. Wobei man die USA ausklammern kann, weil dort noch geklärt wird, ob und was überhaupt reguliert wird.
Brüssel hat sich an der DSGVO orientiert, zunächst einmal nicht zu Unrecht: Denn der Datenschutz wird in der EU, trotz Lücken und Komplexitäten, in allen Bereichen angewendet - egal ob am Arbeitsplatz oder auf Webseiten.
Der “AI Act” geht in seiner horizontalen Betrachtung von verschiedenen Risikostufen aus:
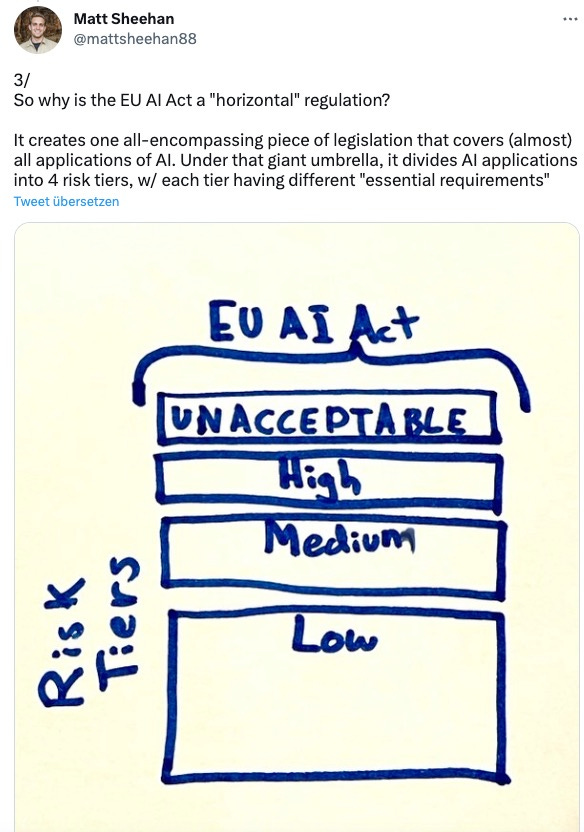
Diese Risikostufen sollen dann durch Standards ergänzt werden, geht dadurch also auch ein bisschen ins Horizontale über.
Dass diese Regulierung an ihre Grenzen stoßen könnte, zeigt sich durch den Erfolg von LLMs. “General Purpose AI”, kurz GPAI (konkret in der Regel Foundation Models), wurde als Kategorie erst im ersten Halbjahr 2022 eingeführt, als klar war, dass es für die Anwendungen mit generativer KI eine eigene Klasse geben musste.
Aber: Wo genau die Risikobewertung bei GPAI ansetzt, beim Modell selber oder bei jeder einzelnen abgeleiteten Anwendung, ist gar nicht so einfach zu entscheiden.
Noch deutlicher wird das Dilemma bei Haftungsfragen: Liegt die Haftung für eine von Chat-GPT gespeisten App bei Chat-GPT selber, weil man de facto “das Gehirn” der Applikation liefert? Eigentlich kann die Firma nicht kontrollieren, wie ein LLM genutzt wird. Umgekehrt gilt aber auch: Der Anbieter der Applikation kann nicht wissen, ob Chat-GPT alle Regulierungsvorgaben erfüllt (z.B. hat man keinen Einblick in die Lerndatenbasis). Und hat entsprechend auch Argumente gegen die eigene Haftung.
Kurz: Es zeichnet sich jetzt schon ab, dass eine Regulierung für alle Anwendungsfälle dieser Technologie schnell an die Grenzen kommt - oder alleine aufgrund der Masse wegen kaum zu bewältigen ist. Zumal “Künstliche Intelligenz” in der bisherigen EU-Definition nicht nur maschinelles Lernen meint, sondern auch bestimmte statistische Verfahren.
Die vertikale Regulierung, wie sie China vollzieht, funktioniert anders: Sie wählt sich bestimmte Gebiete algorithmischer Anwendungen aus und reguliert deren Anwendung in bestimmten Kontexten. Die EU versucht also eine allgemeine Regulierung zu finden, China geht problembasiert vor.
Bei generativer KI (also so etwas wie Midjourney) gibt es zum Beispiel Regeln zu “schädlichem Content” und die Vorgabe, dass Betroffene zustimmen müssen, wenn ihre Bilder oder Stimmen algorithmisch manipuliert werden (Deepfakes). Aber auch hier gibt es ein horizontales Element: Eine Datenbank, in der die KI-Systeme katalogisiert werden (z.B. mit Informationen über Trainingsdaten etc.).
Auch Chinas Ansatz ist umstritten, weil er in gewissen Bereichen als Zensurwerkzeug betrachtet werden kann: So lautet eine der neuen Vorgaben für Chat-GPT-artige Systeme, die in China künftig eingesetzt werden, dass sie “sozialistische Werte” verkörpern müssen. Und auch in demokratischen Ländern kann der vertikale Ansatz dazu führen, dass jede zuständige Institution bei KI-Regulierung in ihrem Bereich das Rad neu erfindet.
Ich selber bin inzwischen dennoch überzeugt, dass vertikale Regulierung die bessere Herangehensweise wäre. Wie man mit GPAI umgehen könnte, werde ich in einer der nächsten Ausgaben aufschreiben.
KI-Hörempfehlung
Hier ein sehr guter Podcast mit Ezra Klein. Wie schön es wäre, wenn das der Standard für die Debatten wäre - informiert, nüchtern, klar verständlich, konkret.
Und ja: Die Folgen, wenn LLM-Systemen als ständige Begleiter agieren, sind gegenüber Folgen der Automatisierung oder gar Endzeit-Szenarien zu priorisieren.
Ich habe es in Newsletter #40 so formuliert:
“[Die LLM-Chatbot-Verbreitung] findet nicht im luftleeren Raum statt. Sondern in Gesellschaften, deren Mitglieder die Bildschirm-Interaktion immer stärker priorisieren. Die Wahrscheinlichkeit eines gesellschaftlich erlebten “Her”-Szenarios wächst wahrscheinlich mit dem Grad unserer Vereinzelung. Und es könnte schwierig werden, sich einer solchen Massen-Adaption anthropomorphisierter Vorstellungen zu entziehen.”
Twexit und die logistischen Hürden
Es gibt in Brüssel offenbar Anzeichen, dass Twitter sich absehbar aus der EU zurückziehen könnte, weil die Einhaltung des Digital Services Act zu aufwändig wäre. Das wäre ein interessantes Szenario, denn für einen solchen Rückzug gibt es meines Wissens nach keine Blaupause.
Es wäre sogar ziemlich kompliziert. Angenommen, Twitter löst seine europäischen Firmenteile auf: Das heißt noch nicht, dass der Dienst in der EU nicht mehr verfügbar wäre. Würde Twitter aber einfach unkontrolliert weiterlaufen, würden meiner Ansicht nach die logischen DSA-Strafmaßnahmen (Artikel 76-82) ins Leere laufen, weil sie eine direkte rechtliche Handhabe auf EU-Hoheitsgebiet voraussetzen.
Thierry Breton (der allerdings nicht der detaillierten Digitalexpertise verdächtig ist) hat im vergangenen Jahr für einen solchen Fall Abschaltungen ins Spiel gebracht. Aber es ist unklar, wie die aussehen würden. DNS-Sperren würden sicher als gigantische Zensurmaßnahme wahrgenommen und Musk als der Gegner der Regierungszensur dastehen lassen, der er nicht ist.
Twitter in den App-Stores zu sperren würde wiederum den Weg über das WWW und bereits installierte Clients offen lassen (mal abgesehen davon, dass die alternativen App-Stores, die durch das EU-Recht auf Sideloading kommen werden, das Ganze also nochmal komplizierter zu überprüfen wäre). Müsste man darauf hoffen, dass Twitter selbst Geoblocking für EU aktiviert?
Ich würde die Spekulationen über ein Twitter-Aus auch erstmal nicht zu hoch hängen. Aber ob wir von Twitter, TikTok, Telegram oder einem uns jetzt noch unbekannten Dienst reden: Irgendwann wird es einen europäischen Prädezedenzfall geben. Ist man in Brüssel auf das Erdbeben vorbereitet, dass man damit auslösen würde?
Loch im Cookie
“Pay or Okay“: So nennt sich das Modell, bei dem Nutzer auf Medienseiten zwischen Cookie-Einwilligung und einem werbefreien Abo wählen können. Der österreichische Standard gilt hier als Pionier - und nun muss nun nach einem (wenig beachteten) Bescheid der Datenschutzbehörde DSB nachjustieren. Zwar stellt die DSB das Modell nicht grundsätzlich in Frage, verlangt aber, dass Nutzer speziell der einzelnen Datenverarbeitung zustimmen müssen. Kurz: Alle Cookies an oder Abo abschließen, das geht nicht mehr. Die Schrems-Organisation noyb, die das Verfahren angestrengt hatte, wird nun absehbar auch in Deutschland ähnliche Ergebnisse erreichen.
Ich hatte es in Nummer #35 angerissen, als der Europäische Datenschutzausschuss Meta wegen der Ganz-oder-garnicht-Einwilligung abgestraft hatte: Das ganze Thema Einwilligung und Cookie-Auswahl steckt nicht nur voller dubioser Umsetzungspraktiken, sondern auch voller Widersprüche. Vom Schrems-Argument “Pay or Okay heißt, ich kaufe mir für viel Geld meine Privatsphäre zurück” halte ich zwar nicht viel. Aber wenn man die Messlate für eine spezifische Einwilligung wirklich so hoch legt, wie sich in den letzten Monaten andeutet, dann ist “Pay or Okay” eigentlich nicht mehr umsetzbar.
Links
Zwei LLM-Takes: Künstliche Intelligenz formt Popkultur und verstetigt Ideologie.
Auch Žižek schreibt etwas dazu. (€)
Der europäische Datenschutzausschuss bildet eine Taskforce zu Chat-GPT.
Warum der “Brussels Effect” in Sachen Regulierung überschätzt wird.
Die Diskussion über das Urheberrecht an KI-Trainingsdaten nimmt Fahrt auf (mit Reddit). Karma?
Stoppt die AI-Business-Influencer!
Zwei Pentagon-Leaks-Takes: Sicherheitslücken sind auch “sozial” und Gruppenchats entwickeln die seltsamsten Dynamiken.
Nach Covid und den Entlassungen: Es wird ruhiger in der Bay Area.
Der Hype um Be Real ist vorbei
Bis nächste Woche!
Johannes