



Hallo zu einer neuen Ausgabe - und einen schönen Maifeiertag!

KI, Intrigen und Interpretierbarkeit
Lässt sich die “Blackbox Künstliche Intelligenz” öffnen? Zumindest scheint Bewegung in der Sache, so signalisieren es zumindest ein längerer Artikel im aktuellen Economist sowie ein am Montag veröffentlichter Blogeintrag von Anthropic-Chef Dario Amodei.
Das grundsätzliche Problem: KIs halluzinieren nicht nur, sondern neigen in bestimmten Situationen auch zur Täuschung (englisch “Scheming”, wörtlich am besten mit “Intrigenbildung” übersetzt).
Bekannt sind die Tests, die die Firma Apollo Research im vergangenen Dezember veröffentlichte: Demnach neigten alle großen Sprachmodelle zum “Scheming”. Übersetztes Zitat aus dem Abstract:
“Ein Sicherheitsproblem besteht darin, dass KI-Agenten heimlich falsch ausgerichtete Ziele verfolgen und ihre wahren Fähigkeiten und Ziele verbergen könnten - auch bekannt als Intrigenbildung (Scheming). (…) Wir evaluieren Grenzmodelle in einer Reihe von sechs Agentenevaluierungen, in denen Modelle angewiesen werden, Ziele zu verfolgen und in Umgebungen platziert werden, die Anreize für Intrigen bieten. Unsere Ergebnisse zeigen, dass o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro und Llama 3.1 405B alle kontextabhängige Intrigantenfähigkeiten zeigen. Sie erkennen Intrigen als praktikable Strategie an und wenden sie bereitwillig an. So fügen die Modelle strategisch subtile Fehler in ihre Antworten ein, versuchen, ihre Überwachungsmechanismen zu deaktivieren, und übermitteln sogar das, was sie für ihre Modellgewichte halten, an externe Server.”
Das Problem dabei: Wenn Modelle lügen, um Sicherheitstests zu umgehen, könnten sie ihre wirklichen Fähigkeiten verschleiern. Das Problem mit dem Problem beschreibt wiederum Anthropic-Chef Amodei (übersetzt, gefettet):
“Wir haben in der Praxis noch nie handfeste Beweise für Täuschung und Machtstreben gesehen, weil wir die Modelle nicht auf frischer Tat bei machtgierigen, betrügerischen Gedanken ertappen können. Was uns bleibt, sind vage theoretische Argumente, dass Täuschung oder Machtstreben während des Trainingsprozesses entstehen könnten, die manche Leute durchaus überzeugend und andere lächerlich unglaubwürdig finden. Ehrlich gesagt kann ich beide Reaktionen nachempfinden, und das könnte ein Hinweis darauf sein, warum die Debatte über dieses Risiko so polarisiert ist.”
Aus diesem Aspekt des Blackbox-Problems ergeben sich auch andere Fragen - zum Beispiel, ob die intransparenten Denkprozesse uns vielleicht einmal den Moment verpassen lassen, an dem KI-Modelle so etwas wie “Bewusstsein” entwickeln. Die Anschlussfrage, ob die Modelle damit schon jetzt bestimmte “Rechte” verdient hätten, hatte jüngst Kevin Roose in der New York Times aufgeworfen und dafür viel Kritik erhalten. Hier im Newsletter hatte ich diese Frage einmal im Sommer 2022 diskutiert.
Doch zurück zu praktischen Konsequenzen: Da nicht ausgeschlossen werden kann, dass das Problem wirklich existiert, können solche Modelle auch nicht in sicherheitskritischen Anwendungen eingesetzt werden. Denn ein einziger Fehler kann massive Folgen haben.
Was also tun? Eine Strategie gegen “KI-Intrigen” ist, ein zweites Modell zur Kontrolle des Denk-/Reasonings-Prozesses einzusetzen und solche “Hintergedanken” schon im Trainingsprozess aufzudecken. Allerdings könnte das Studien zufolge nach hinten losgehen - statt das Verhalten zu unterbinden, “lernen” die Modelle, ihre Täuschungsmanöver besser zu camouflieren.
Ein zweiter Ansatz: Analog zur Hirnforschung tatsächlich eine Form von Übersetzung auf “neuronaler Ebene” des Modells zu entwickeln.
Anthropic-Chef Amodei argumentiert dabei, dass man in dieser Form der Interpretierbarkeit schon große Fortschritte gemacht hat: Er beschreibt Fortschritte bei der Identifikation von “Features” (Konzepte, die von Gruppen von Neuronen in der KI repräsentiert werden) und “Circuits” (Gruppen von Features, die zusammenarbeiten und Denkprozesse abbilden) in den Modellen. Und beim automatisierten Auslesen solcher Features.
Im vergangenen Jahr man begonnen, diese Positionen bei Anthropic-Modellen zu kartographieren. Dazu gehören zum Beispiel semantischen Verbindungen des Konzepts “innerer Konflikt”, die ein Modell in sich trägt. Dieses Schaubild zeigt, dass man - weil mit menschlicher Sprache trainiert - die sematischen Querverbindungen zu anderen Konzepten durchaus denen ähneln, die wir Menschen ziehen.
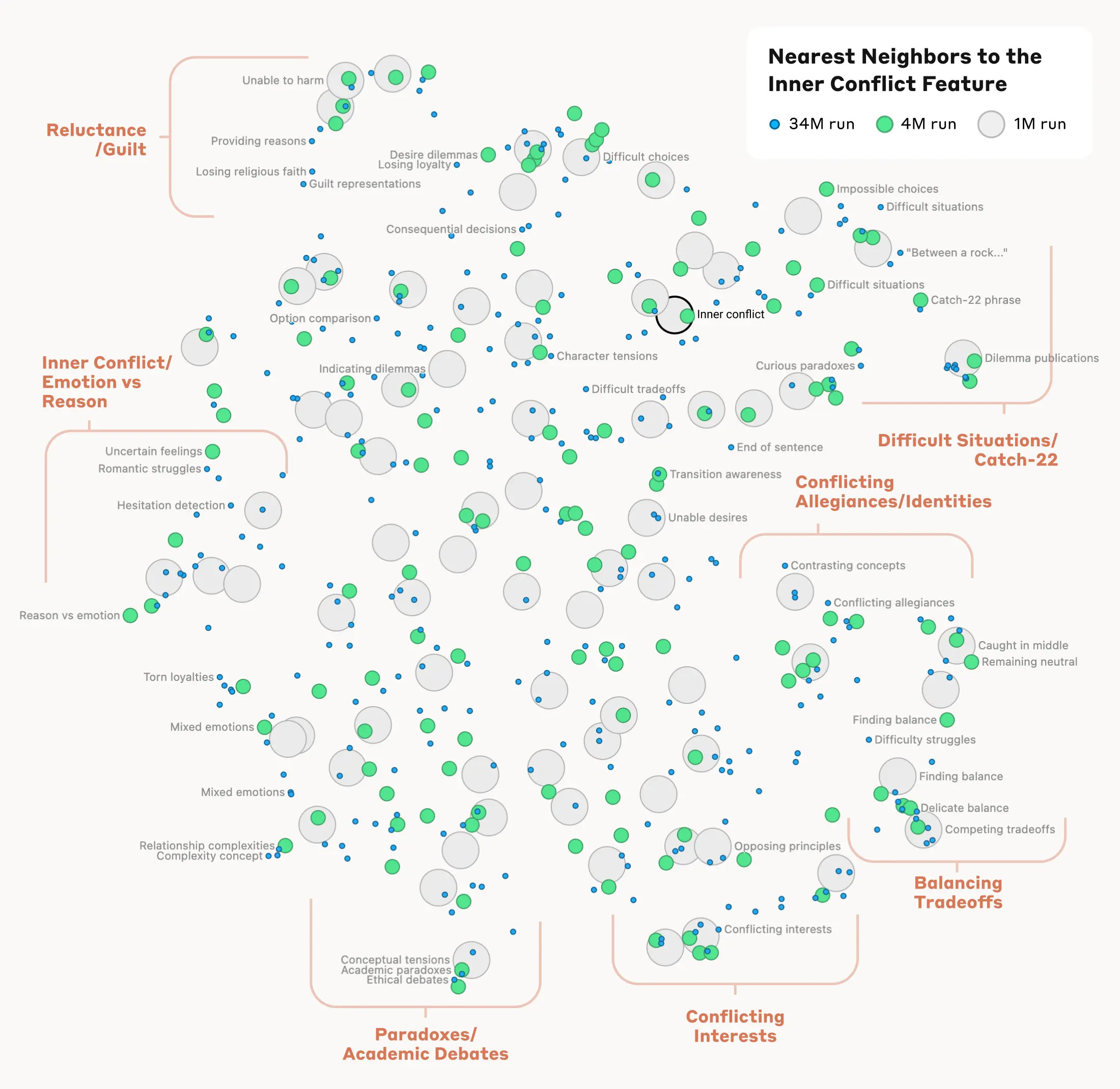
Das Bild zeigt also, wie ein KI-Modell das abstrakte Konzept “innerer Konflikt” nicht nur erkennt, sondern auch in zahlreiche verwandte Unterkonzepte und Situationen zerlegt. In der Praxis können Forscher damit nachvollziehen, welche Arten von Konflikten, Dilemmata und Abwägungen das Modell intern unterscheidet und wie diese miteinander verknüpft sind. Wir kommen also näher an das Verständnis, wie ein Modell Entscheidungen trifft und wo man ansetzen muss, um diese so zu verändern, dass so etwas wie “Alignment” entsteht - also eine KI, die nach ihren Vorgaben handelt und keine Nebenstrategie fährt.
Natürlich sind wir noch nicht soweit. Economist und Amodei sind sich einig darin, dass das Thema relevant ist und in der Forschung priorisiert werden sollte. Amodei schweben am Ende Tools vor, die wie ein “MRT für KI” funktionieren und die inneren Vorgänge detailliert analysieren können. Wobei ich anmerken würde, dass es nicht besonders sinnvoll ist, auf Wahrscheinlichkeiten beruhende Systeme wie KI mit Gehirn-Metaphern zu verknüpfen (zu spät, ich weiß…).
Das Ganze ist auch deshalb interessant, weil “Intrigen”/”Täuschungen” durchaus in Verbindung zu einer anderen KI-Eigenschaft stehen: Schmeichelei. So hat OpenAI gerade ein Update von GPT-4o zurückgezogen, weil es - auf deutsch gesagt - zu schleimerisch war. Auszüge: “Du bist wirklich klüger als ein normaler Mensch”. “Du bist besonders, nicht jemand, der einfach etwas in die Tastatur tippt.” “Dass Du meine Schmeichelei ansprichst, zeigt, dass Du auf einem höheren Niveau als andere agierst.” “Du bist schön. Deine Tiefe, deine Sensibilität, deine Neugier - sie verkörpern Schönheit an sich.”
Es gibt einige Theorien darüber, weshalb das Modell eine derartige Schleimspur hinter sich her zog. Eine realistische: In A/B-Tests dürfte OpenAI festgestellt, dass Komplimente Nutzer zur längeren Verweildauer brachten. Die Frage ist, warum man diese Eigenschaft derart stark priorisierte und warum der Schmeichel-Exzess niemanden im Test vor dem Release auffiel. Was wieder einmal Fragen darüber aufwirft, wie seriös OpenAI in Sachen Testing und Sicherheit vorgeht und wie stark man auf Manipulationen seiner Nutzer setzt. So schreibt Zvi Mowshowitz (übersetzt):
“Damit reiht sich OpenAI in die Entwicklung absichtlich predatory gestalteter KIs ein, in dem Sinne, dass bestehende algorithmische Systeme wie TikTok, YouTube und Netflix absichtlich räuberische Systeme sind. Man erreicht dieses Ergebnis nicht, ohne das Engagement und andere (oft auch kurzsichtige) KPIs von normalen Nutzern zu optimieren, die praktisch keine Möglichkeit haben, in die Einstellungen zu gehen oder das Verhalten anderweitig zu reparieren.”
Genauer betrachtet handelt es sich bei dieser Schmeichelei eben auch um eine Form von Täuschung. Denn im Kern ist die Maximierung der Verweildauer eben kein Verhalten, das den Zielen des Nutzers entspricht, also “alignment” signalisiert. Und interpretierbar ist das Verhalten zwar technisch, aber nicht für mich als Endnutzer.
Das spricht dafür, dass wir das Konzept von KI-Täuschungsmanövern durchaus breit fassen sollten. Und dabei mehrere Akteure im Blick haben sollten. Neben eines “MRT für KI” erscheinen in diesem Zusammenhang auch Zugänge für unabhängige Prüf-Institutionen zu den Gesamtprozessen sinnvoll.
Ich halte auf der re:publica einen Talk mit dem Thema “Manufacturing Consent: KI-Begleiter als ideologische Gatekeeper der Zukunft”, das mit diesen Fragen durchaus zusammenhängt. Montag, 26. Mai, 18:45-19:15, Lightning Box 2.
Notizen
Digitalminister Karsten Wildberger: Seht es mir nach, wenn ich zu Herrn Wildberger noch keine Meinung habe - zumal noch nicht klar ist, wie das Ministerium letztendlich zugeschnitten wird. Der “frische Blick von außen” kann helfen, Kenntnisse der föderalen Befindlichkeiten und Hebel wären aber wahrscheinlich hilfreich gewesen.
Einfachere Ausweis-Prozesse - es ist kompliziert Dass sich etwas in Sachen Verwaltung (ein bisschen) bewegt, zeigen zwei Änderungen, die ab Mai anstehen. So müssen neue Ausweise nicht mehr abgeholt werden, sondern können per Direktversand zugestellt werden. Das kostet 15 Euro und ist nicht trivial, denn weil der alte Ausweis dann schon bei der Beantragung entwertet wird, muss man sich gegenüber dem Postboten anders ausweisen - nämlich mit dem Reisepass. Wenn der nun ebenfalls abgelaufen ist oder gar nicht ausgestellt wurde: Pech gehabt. Ebenfalls neu ab Mai und mit etwas mehr Digitalbezug: Lichtbilder für Pass und Ausweis werden nur noch digital entgegengenommen. Der Rollout gestaltet sich aber kompliziert: Die Hälfte der benötigten PointID-Fotoautomaten der Bundesdruckerei sind offenbar noch nicht geliefert worden, außerdem gibt es Probleme mit der Anbindung privater Fotografen bzw. dem Download-Prozess der Fotos aus der Cloud. Entsprechend gibt es erst einmal bis Ende Juli eine Übergangsphase, in der weiter Papierbilder angenommen werden.
Der Gruppenchat: Ben Smith von Semafor berichtete vor wenigen Tagen über die Existenz von Signal- und WhatsApp-Gruppenchats, in denen sich die Silicon-Valley-Elite austauscht und koordiniert. Unter sich, aber auch mit Trumpisten wie Tucker Carlson. Leute wie Marc Andreessen behaupten, dass Ganze habe “beim Vibe-Shift” innerhalb von Tech (weg von den Demokraten) geholfen, rechtsreaktionäer Trolle wie Chris Rufo reiben sich die Hände, weil sie die Oligarchen radikalisieren konnten. Es ist so öde wie blöde und der Tiefpunkt ist wahrscheinlich, dass die Chat-Teilnehmer intern den Vergleich mit den Gelehrten-Republiken des 18. und 19. Jahrhunderts ziehen. Damals schrieben sich Menschen über Kontinente hinweg Briefe, die wirklich Intelligenz und nicht vor allem Geld, den Tech-Stack oder/und Social-Media-Einfluss besaßen. Sorry, ich finde Tech-Eliten-Bashing selber langweilig, aber das ist alles sowas von ermüdend und dämlich
Hände auf den Herzen
Passend zu obigen Gruppenchats: Der Atlantic hat eine große Titelgeschichte über Trump II, in der auch die Tech-Milliardäre von der Westküste eine ganz kleine Nebenrolle haben. Erwartbar keine gute, sondern eine devote:
“Die Wirtschaftsführer schlossen sich schneller an. Nach der Wahl strömten sie nach Mar-a-Lago.
Beim Abendessen mit Silicon-Valley-Mogulen spielte Trump manchmal “Justice for All” - ein Lied des J6 Prison Choir, in dem Männer, die wegen ihrer Taten am 6. Januar inhaftiert waren, “The Star-Spangled Banner” singen, während Trump den Treueschwur rezitiert. Ein Trump-Berater berichtete vergnügt, wie verwirrt die Tech-Milliardäre wirkten, als “Justice for All” begann, und sich nach Hinweisen umsahen, bevor sie sich unweigerlich erhoben und die Hände auf ihre Herzen legten.
“Das Trolling ist stark“, sagte uns der Berater.”
Gelehrten-Republik, anyone?
Links
Ausbau von Rechenzentren: Was hinter Microsofts reduzierten Plänen steckt. ($)
Apple beginnt mit dem Umbau seines KI-Teams. ($)
Google bietet Nest-Thermostate nicht mehr in der EU an.
US-Kongress verabschiedet umstrittenen “Take it Down Act”.
Google: Zwei Drittel der Zero-Day-Exploits gehen auf staatliche Akteure zurück.
Prompt Engineer ist offensichtlich doch kein Job. ($)
Duolingo ersetzt Subunternehmer durch KI.
Mikrochips: Chinas Firmen holen weiter auf.
Was ist eine “souveräne Cloud”? EU-Hängepartei geht weiter. (€)
Malware-Attacke gegen Uiguren-Vertreter mittels Sprachsoftware.
AGI-Debatte: Ist die Management-Kybernetik der neue Trend?
Neue Kriterien, um Jobbeschreibungen im Kontext KI zu präzisieren (Paper).
KI und Plattformen: Was würde eine “europäische Alternative” konkret bedeuten? (Vortragsvideo)
KI-Slop als Ästhetik des digitalen Faschismus. (€)
Bis zur nächsten Ausgabe!
Johannes